

IDSS COVID-19 Collaboration (Isolat)
A data-driven approach to addressing the Covid-19 pandemic
In March 2020, as Covid-19 cases were surging worldwide, IDSS organized a volunteer, interdisciplinary team to provide analysis of data associated with the coronavirus pandemic in order to inform policy makers. The ‘IDSS Covid-19 Collaboration,’ dubbed ‘Isolat,’ brought together faculty, postdocs, and students from across IDSS, MIT, and around the globe.
Over the course of five months, Isolat met daily to discuss findings from various interconnected research projects. Isolat established a ‘data lake’ that allowed researchers access to many relevant, up-to-date datasets. Isolat brought insight to bear on many aspects of the pandemic, particularly the challenges of Covid testing strategy.
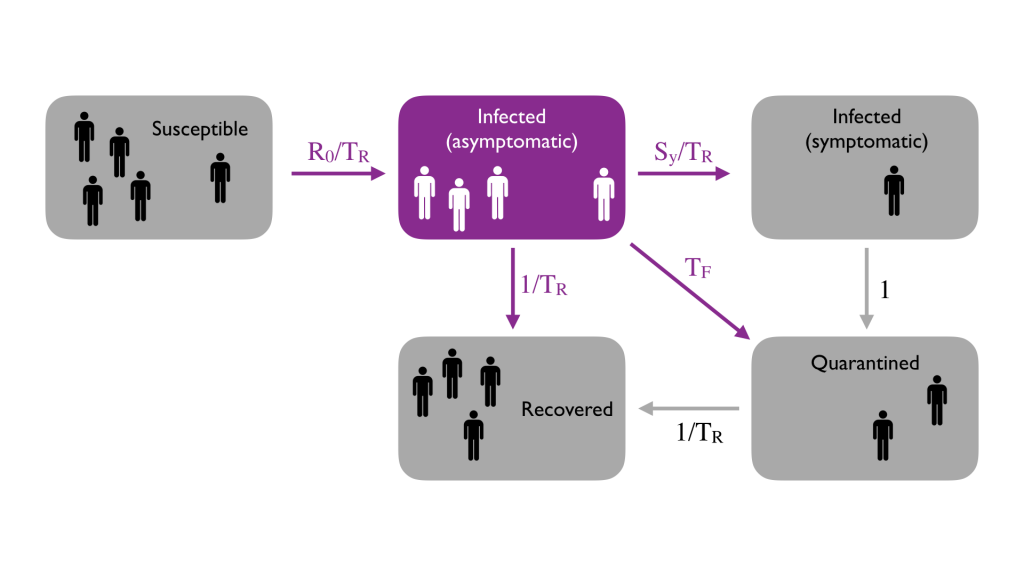
Rules of Thumb for Reopening – Part 1: Testing = Control
Isolat research
Isolat research has looked broadly at pandemic challenges — “everything from the physical mechanism of transmission all the way up to making policy,” says Professor Anette ‘Peko’ Hosoi, one of the founders of Isolat. Different teams worked on forecasting waves or spikes in virus spread, modeling modes of transmission, assessing policies and economic effects, and exploring the impacts on more vulnerable communities to address equity in managing scarce resources.
Isolat has made public:
- a memo on testing strategies
- a Covid predictions dashboard
- a tutorial on epidemic modeling and estimation
Isolat impact
Isolat research findings have had a local, national, and global impact. As MIT navigated the process of bringing students back to campus, Isolat research informed MIT re-opening policy with systems thinking and data analysis. Isolat research has been shared with other colleges and with governments both local and global.
Isolat entered a second phase in September when IDSS welcomed a new alliance member: the Consortia for Improving Medicine with Innovation and Technology (CIMIT).
Joining the IDSS Alliance helped CIMIT and IDSS learn about each other’s capabilities. CIMIT and IDSS researchers, led on the IDSS side by Professor Hosoi, then developed a tool to help organizations like schools, businesses, and factories make rational decisions and implement successful strategies for Covid-19 testing. The Covid-19 Testing Impact Calculator on whentotest.org.
Read more about Isolat’s impact.

